关于内存配置器的一些总结
概述
内存管理
我们通常说的内存管理是操作系统内核提供的功能之一,也就是对于虚拟内存的管理。可以 分为以下几个不同的层次。
- 操作系统: 内核对虚拟内存的管理,通过系统调用为库函数或用户程序提供服务
- C库函数: 函数虚拟内存进行管理,避免频繁使用系统调用带来的开销
- 用户程序: 用户程序先通过系统调用申请一大块内存,然后自己来管理这块内存
内存配置器
我们通常把用来管理内存的对象称为内存配置器,一个设计良好的内存配置器 应该满足如下要
- 内存碎片尽可少
- 良好的本地缓
- 额外的内存碎片尽可能少
- 通用性,兼容性,可移植性,易调试
重要性
系统的物理能内存是有限的,但是对内存的需求是动态的,动态性越强,内存管理的重要性 越强。我们设计的程序对内存的申请需求是不一样的,因此选择合适的内存配置,可以更好 的发挥应用程序的性能。
本文简单地分析目前常用的几个内存配置器,包括 ptmalloc2,tc_malloc,jemalloc。
ptmalloc2
目前 ptmalloc2 是 glibc 这中 malloc 的默认内存配置器,在之前还有一些其它的实现如 dlmalloc 等。但由于多核的出现,而 dlmalloc 没有针对多线程的实现。因此已经退出历 史舞台。为了比较当前比较优秀的配置器,选择了 ptmalloc2 。
内存管理对象
在 ptmalloc2 中的内存管理对象叫做 arena , 在 arena 中有一个空闲链表数组 bits ,每一个 链表称为一个 bin 。每个 bin 管理多个固定大小的 chunks。
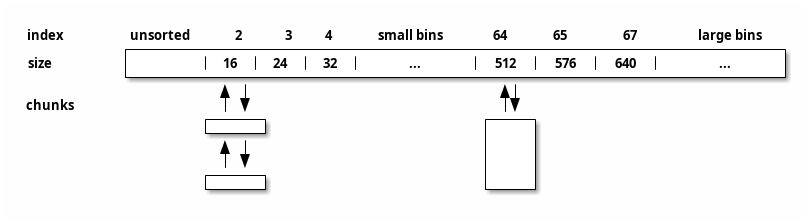
如上图所示, ptmalloc2 将 bins 划分为三部份, unsorted bin , small bins 以及 large bins 。其实还有一个 bin , 称为 fast bin 。 ptmalloc2 将不大于 64 B 的 chunk 先放到 fast bin 中加快分配速度。
多线程处理
在 ptmalloc2 中,多线程的处理方式是在每一个线程中维护一个 arena 。在主线程中维护
主分配器 main arena , 在其它线程中维护副分配器 thread arena 。 thread arena 中的
内存只会通过 mmap 在映射区获取一块 HEAP_MAX_SIZE 大小的内存作为该线程的私有内
存池进行管理。 main arena 如果内存不够通过调用 sbrk 进行扩容。
分配流程
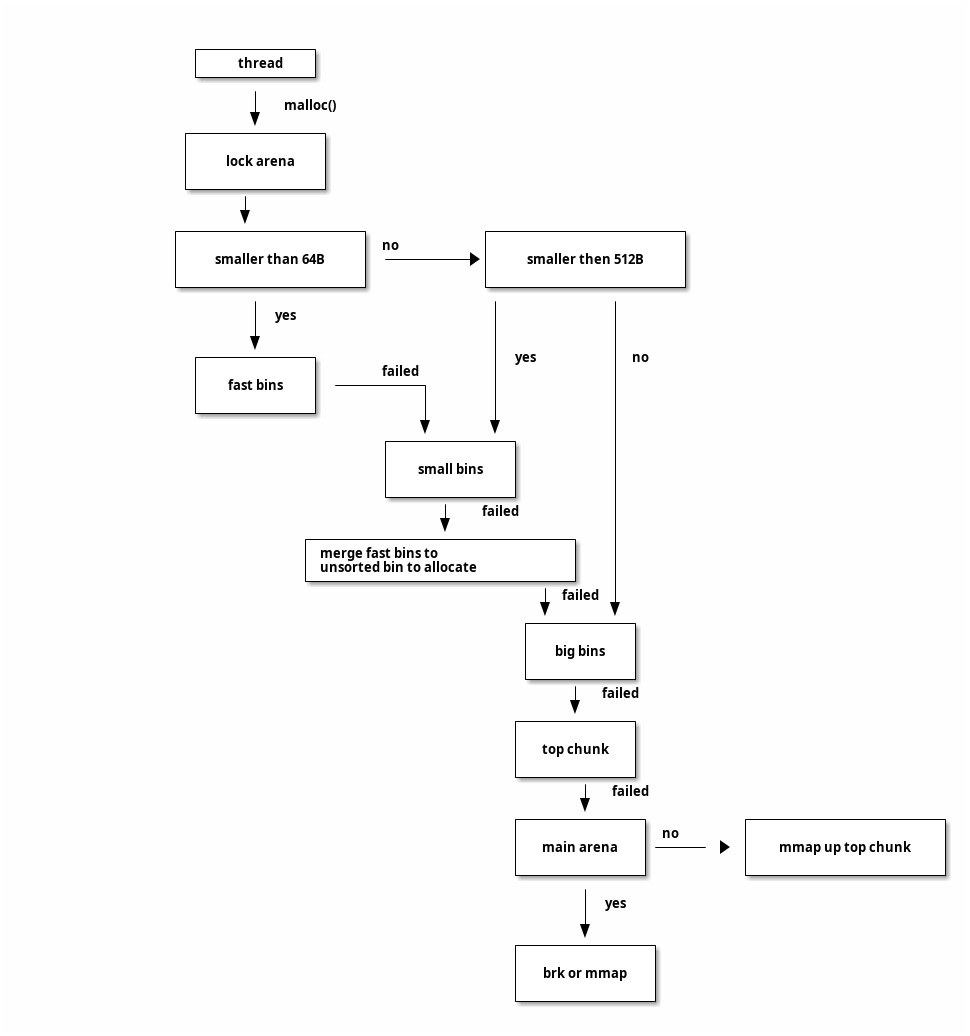
系统回收
每一个 arena 都有一个 top chunk ,用来保存堆顶的块,当释放的内存和 top chunk 相邻 ,则将其合并到 top chunk, 当其大小超过阈值时,将其释放给操作系统。
缺点
- 只能从后分配的内存开始释放
- 多线程开销大,ptmalloc2 并不是严格的每个线程一个 arena,而是在线程第一次申请内 存时,判断是否有可用的 arena , 如果有直接加锁使用;没有则分配一个 arena.
- 内存不能从一个 arena 转移到另一个 arena. 导致多线程内存使用不均衡
- 至少 8 字节的额外开销
- 不定期分配长时间的内存容易造成内存碎片
tcmalloc
tcmalloc 是 Google 开源的一内存管理库,地址:https://github.com/gperftools/gperftool
ThreadCache
tcmalloc 为每个线程都分配一个线程本地的内存池 threadCache, 用于分配小内存。这样 在多线程时,可以减少对内存管理器加锁解锁的开销。当然, threadCache 只用于小对象 的分配, size <= 32KB . 在 threadCache 中维护一个空闲链表数组,每个对象称为 size-class. 这个和 ptmalloc2 中的 bin 作用一样。
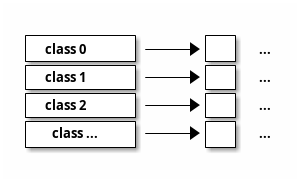
分配流程
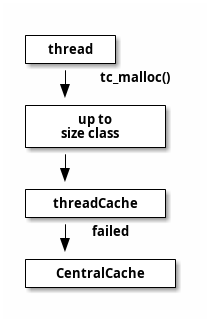
CentralCache
tcmalloc 除了在每个线程分配一个本地分配器,整体还分配一个中央配置器, CentralCache 用来分配大对象的,管理的内存单元时 4K 对齐的,如果 ThreadCache 中的 内存不够,需要到 CentralCache 中获取对应 size-class 的内存。

rest 链表挂接大于 255 个 pages 的页面。
分配流程
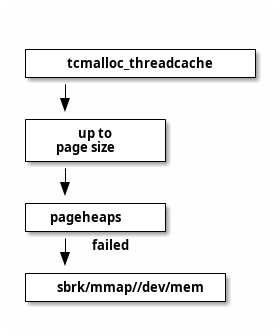
回收内存

优点
- ThreadCache 会阶段性的回收内存到 CentralCache 中,解决 ptmalloc2 中 arena 不能 迁移问题
- 占用很少的空间,约 1%
- 快,小对象几乎无锁
jemalloc
原理和 tcmalloc 差不多,都是在 < 32KB 时无锁使用本地 cache. 差别主要是在 size-class 的分类上不一样。地址: https://github.com/jemalloc/jemalloc
size-class
- Small: [8], [16,32,…,138], [192,256,…,512], [768,1024,…,3840]
- Large: [4K, 8K, … , 4072K]
- Huge : [4M, 8M, … , …]
- small/large 对象查找 metedata 需要常数时间
- Huge 对象通过全局红黑树在对数时间内查找
jemalloc 中对象的关系
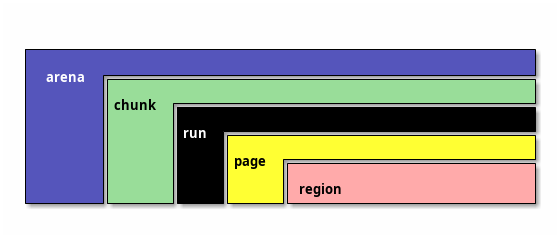
分配流程和 tcmalloc 大同小异。
优点
- 低地址优先策略,降低内存碎片花, tcmalloc 采用 best fit
- 额外开销约 2%
- 和 tcmalloc 一样的本地缓存,避免竞争
- 优先使用脏页,提升缓冲命中
总结
ptmalloc2, tcmalloc 以及 jemalloc 都是比较出色的内存配置器,据 tcmalloc 官网公布 数据, tcmalloc 的速度是 ptmalloc2 的数倍,主要还是出色的多线程本地缓存设计。对 于释放内存方面,ptmalloc2 比后两者要差的多,因为它只能从 top chunk 释放。 tcmalloc 和 jemalloc 性能差不多,但是 jemalloc 在提升缓存命中中设计的比较巧,可 能这也是它稍快于 tcmalloc 的原因吧,不过官网的测试数据也可能是使用的 tcmalloc 的 版本比较低。总之,内存配置器是一个程序优化很重要的一部分,选择合适的内存配置器将 提升程序的性能,如果自己的程序对内存有特殊要求,可以基于这些配置器实现自己的内存 管理配置器,甚至直接使用系统调用来自己管理。不过如非特定需要,尽量用现有的轮子, 内存配置器涉及不好,将事倍工半。