Linux 内核设计与实现 — 内核同步
在进行多线程编程时,我们要特意留意共享数据的保护,防止并发访问时多个线程同时操作 导致的结果不一致性。 Linux 2.0 开始内核开始支持 SMP. 所以内核可以在同一时刻运行 多个内核线程。因此内核的共享数据的保护显得尤为重要。
基本概念
- 临界区:访问和操作共享数据的代码段
- 竞争:两个或多个线程对临界区的同时访问
- 同步:避免并发和防止竞争
同步方法
原子操作
原子指不可分割的执行序列,原子操作可以保证指令以原子的方式执行。
原子整型操作
只能对类型为 atomic_t 的数据进行处理。不使用 int 原因如下:
- 确保只与这种特殊类型的数据一起使用,这样保证该类型的数据不会被传递给任何非原 子函数
- 确保编译器不对相应的值进行访问优化,这使得原子操作最终接收到正确的内存地址, 而不是一个别名。
- 在不同体系结构下实现原子操作时可以屏蔽其间的差异
typedef struct {
volatile int counter;
} atomic_t;
内核提供的接口在 <asm/atomic.h> 中:
{{ figure src= “/images/截图_2019-06-12_21-08-15.png” >}}
能使用原子操作时尽量使用,相比于其它的加锁机制。原子操作与复杂的同步方法系统开 销更小,对高速缓存的影响也很小。原子操作大部分是内联函数,内嵌汇编代码。
64位原子操作
typedef struct{
volatile long counter;
}atomic64_t;
使用方式和 atomic_t 一样,只是将名称都改为 atomic64_t.
原子位操作
位操作是对普通内存地址进行操作。参数是一个地址和位号。只要指针指向目标数据,就可 以对其操作。 {{ figure src= “/images/截图_2019-06-12_21-23-14.png” >}}
内核同时还提供了非原子位操作,函数名称是上述函数前前面加上双下划线。如
test_bit() 的非原子形式为 __test_bit(). 它通常比原子操作快些。
自旋锁
Linux 内核中最常见的锁。最多只能被一个可执行线程持有。如果一个线程试图获取一个被 占用的自旋锁,那么就会陷入忙循环-旋转-等待锁重新可用。
使用:
DEFINE_SPINLOCK(mr_lock);
spin_lock(&mr_lock);
/* 临界区 */
spin_unlock(&mr_lock);
Linux 内核实现的自旋锁是不可递归的。
可以用在中断处理程序中(不能使用信号量,因为会导致睡眠)。在获取自旋锁之前,必须 禁止本地中断(当前处理器),否则中断处理程序就会打断有锁的内核代码,有可能试图去争取这个已经被 占用的自旋锁,这样中断处理程序就会自旋等待该锁重新可用;但锁的持有者在这个中断程 序处理完之前不可能运行。

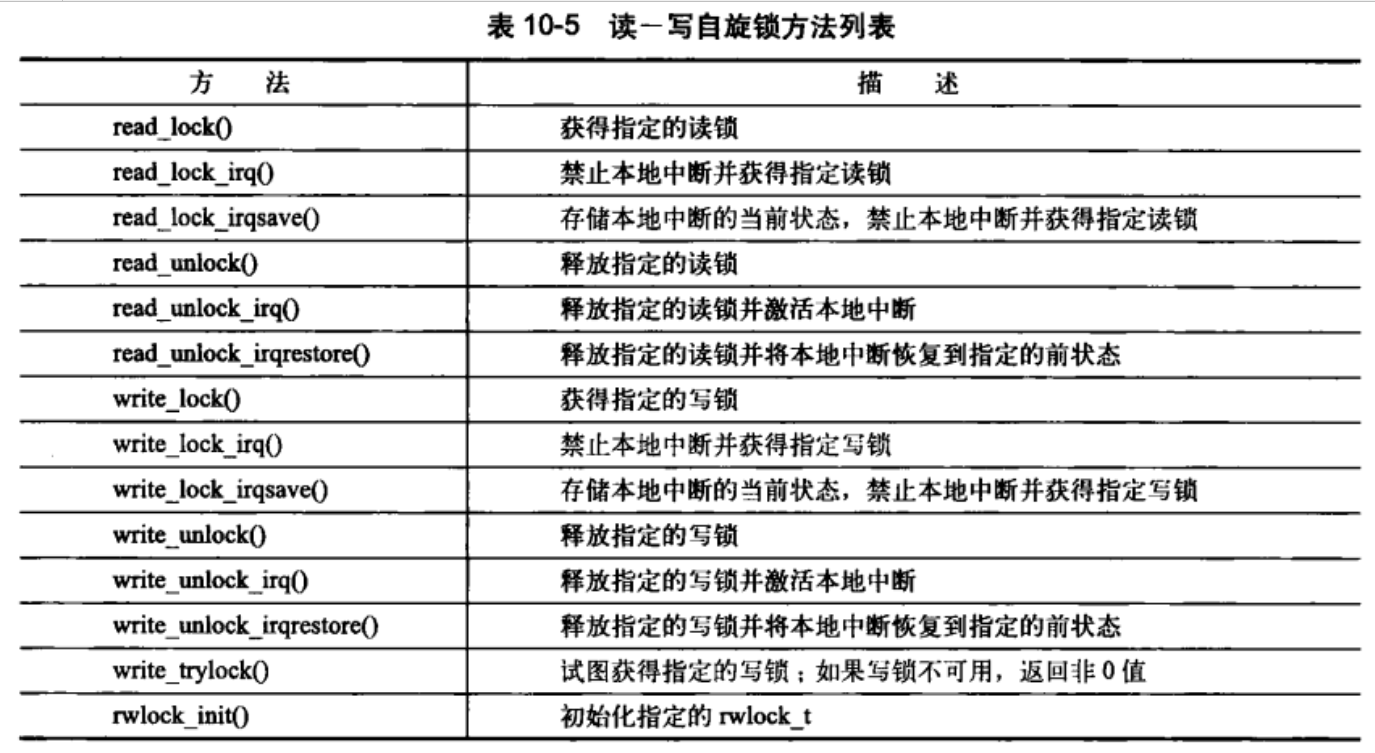
读写自旋锁
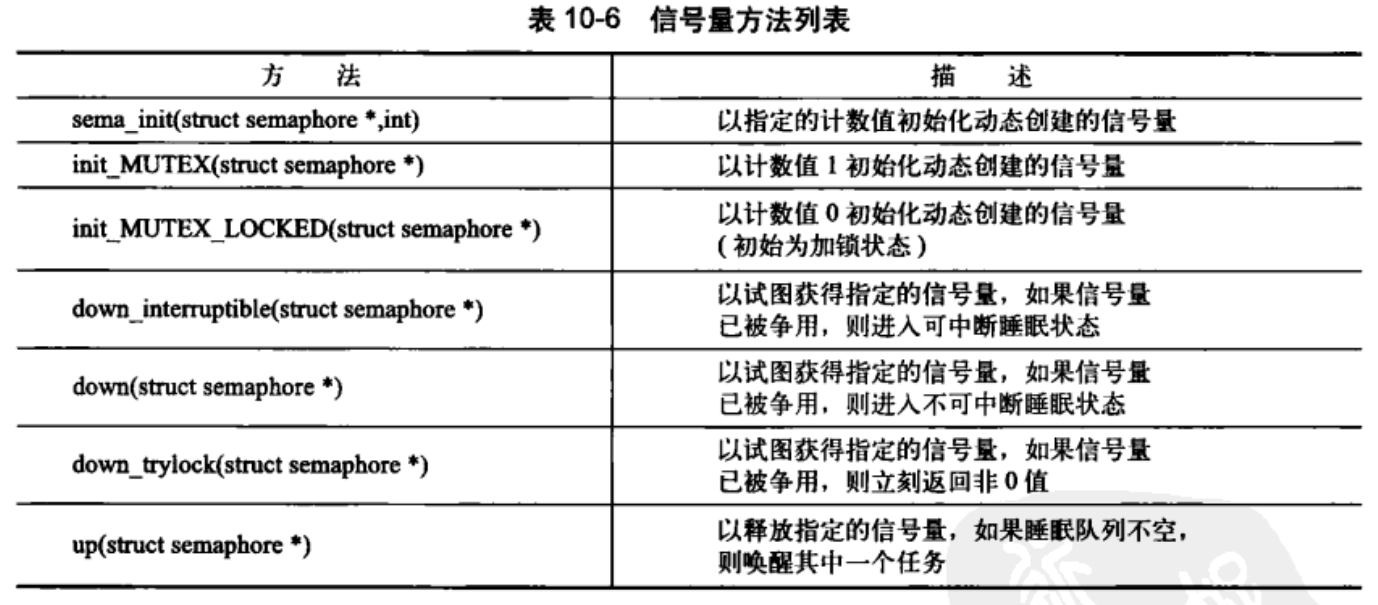
信号量
Linux 中的信号量是一种睡眠锁,如果一个任务试图获取不可用(被占用)的信号量时,信 号量会将其推进一个等待队列,然后让其睡眠。当持有信号量的任务释放信号量后,处于等 待队列中的任务将被唤醒并获得信号量。
- 争用时会睡眠,所以适用于锁会被长时间持有的情况
- 相反,短时间持有时,就不适合了,因为睡眠、维护等待队列以及唤醒的开销可能比锁 占用的时间还长
- 由于执行线程会睡眠,所以只能在进程上下文中获取信号量锁,因为在中断上下文是不 能调度的
- 在持有信号量时睡眠,因为其它等待进程不会因此死锁
- 占用信号锁的同时不能占用自旋锁,因为等待信号量时有可能睡眠,而持 有自旋锁不能睡眠
计数信号量和二值信号量
二值信号量又称互斥信号量,表示同一时刻只能有一个线程持有该锁。
读写信号量
和读写自旋锁一样,将信号量细分为读写两个步骤进行加锁
互斥体
是一种比互斥信号量简洁高效的互斥锁;行为和互斥信号量类似,但接口比互斥信号量简单;

互斥体的使用场景相对而言更严格、定向:
- 任何时刻只有一个任务持有
mutex,即mutex的计数永远为 1 - 给
mutex上锁者必须负责解锁,即不能在一个上下文加锁,而在另一个上下文解锁。 这使得mutex不适合内核同用户空间复杂的同步场景 - 不允许递归的上锁和解锁
- 当持有一个
mutex时,进程不可以退出 mutex只能通过官方 API 管理,不可拷贝、手动初始化或者重复初始化
最有用的特色是:通过一个特殊的调试模式,内核可以采用编程方式检查和警告任何践踏其 约束法则的行为。
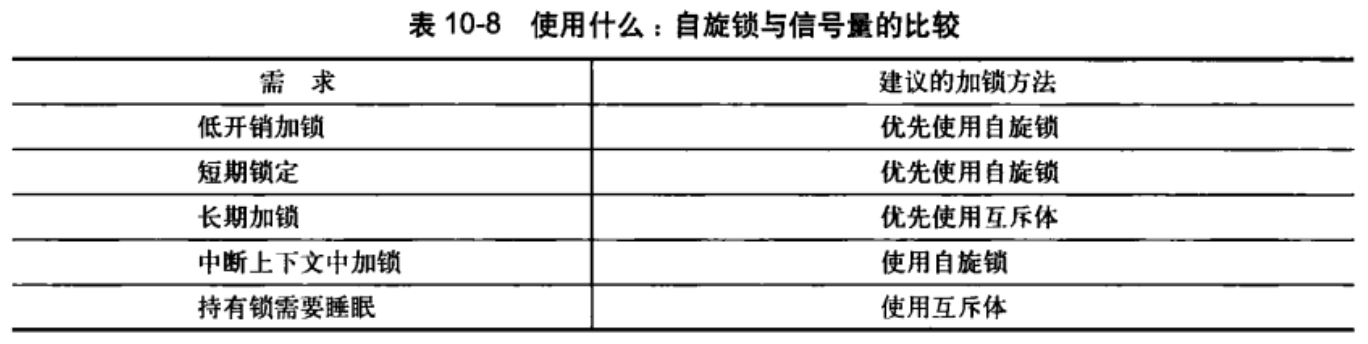
对于信号量和互斥体的选择:首选互斥体,除非它的约束条件不够
自旋锁和互斥体的选择:
完成变量
用于一个任务发送给另一个任务发生某个特定事件的信号。他是信号量的简单替代解决方案, 如子进程执行或退出时使用完成变量唤醒父进程。
通常的用法是:将完成变量作为数据结构中的一项动态创建,而完成数据结构初始化工作的
内核代码将调用 wait_for_completion() 进行等待。初始化完成后,初始化函数调用
completion() 唤醒等待的内核任务。

大内核锁(BKL)
是一个全局自旋锁,主要是为了方便实现从 Linux 最初的 SMP 过渡到细粒度加锁机制。 BKL 多数情况下像是在保护代码而不是数据。这也是使用自旋锁代替 BKL 的困难之处。
- 持有 BKL 的任务可以睡眠。因为当任务无法调度时,所加锁会被自动丢弃;当任务被调 度时,又会重新获得。
- BKL 是一种递归锁。可以多次请求一个锁,不会像自旋锁那样产生死锁
- 只可以用在进程上下文,这点不同与自旋锁
- 新的用户不允许使用 BKL, 现在已经很少有驱动和子系统依赖与 BKL 了

顺序锁
简称 seq 锁,2.6 版引入的新型锁。是一种用于保护读写共享数据的简单机制。实现主
要依靠一个序列计数器,当有疑义的数据被写入时,会得到一个锁,并且序列会增加。在读
取数据之前和之后,序列号都被读取。如果读取的序列号值相同,说明在读操作进行的过程
中没有被写操作打断过。此外,如果读取的值是偶数,就表明写操作没有发生(即初始值是
0,写锁变为奇数,释放再变为偶数)
应用场景:
- 存在很多的读者
- 写者很少
- 虽然写者少,但希望写优于读,且不允许读者让写者饥饿
- 数据很简单。
禁止抢占
使用一个自旋锁可以避免内核抢占,但是这会使全部的处理器均不可抢占该临界区。但有时 候我们只想保护某个处理器上的数据,那么我们可以使用在某个处理上禁止内核抢占即可。

preempt_disable() 可以嵌套调用,可以调用任意次,但必须有相应的
preempt_enable() 调用。抢占计数存放着被持有锁的数量和 preempt_disable() 的调
用次数,如果计数是 0, 表示内核可抢占。
还有一种简单的方法是使用 get_cpu() 和 put_cpu(), 在 get_cpu() 返回前会关闭
内核抢占,使用 put_cpu() 开启内核抢占。
int cpu;
cpu = get_cpu();
/* 对处理器上的数据进行操作 */
put_cpu(); /* 开启内核抢占 */
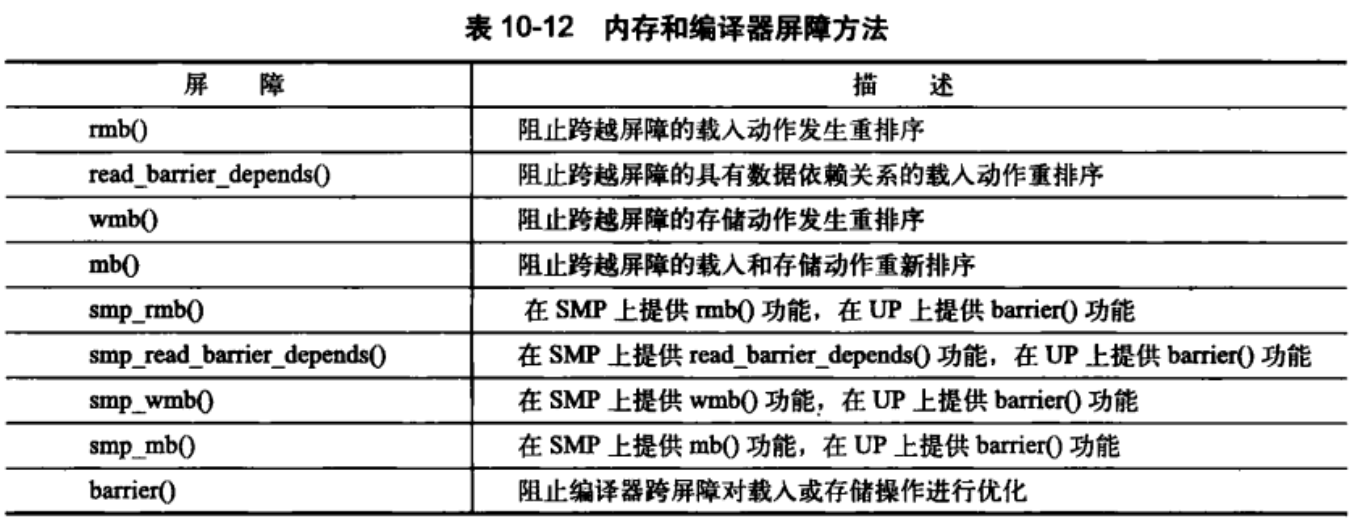
顺序和屏障