Linux 内核设计与实现 — 进程调度
进程调度
- 进程是程序的运行态的表现形式
- 进程调用是确保程序有效工作的内核子系统
多任务
- 并发交互的执行多个进程的操作系统
- 抢占式 : 由调度程序决定什么时候停止一个程序,以便其它进程能够得到执行的机 会。强制挂起的动作称为抢占。
- 非抢占式 : 除非进程自己主动停止运行,否则一直运行下去。进程主动挂起的操作称
为让步(yielding)
- 调度程序无法对每个进程该执行多长时间做出统一规定
- 决不做出让步的进程可能使系统崩溃
Linux 的进程调度
- 2.5 版本之前使用近乎原始的调度器
- O(1) 调度器
- CFS 完全公平调度器
策略
决定程序何时运行,决定系统整体印像,负责优化使用处理器的时间。
I/O 消耗型和处理器消耗型
- I/O 消耗 : 大部份时间用来提交 I/O 请求或等待 I/O 请求
- CPU 消耗 : 大部份时间用在代码执行上
调度策略需要在进程响应和系统吞吐之间找到平衡,选择最值得运行的程序投入运行,但并 保证低优先级进程被公平对待。
Linux 对进程的响应做了优化,更倾向于优先调度 I/O 消耗型进程。
优先级
- 优先级范围
- nice 值 : [-20, 19], 默认为 0; 越大优先级越低
- 实时优先级 : [0, 99], 越大优先级越高,且都高于普通进程
时间片
进程被抢占前所能持续运行的时间。
- 过长 : 导致系统对交互式响应表现欠佳
- 过短 : 增大进程切换的开销
Linux CFS 调度器将 CPU 的使用划分给了进程,从而和系统负载密切相关。比例进一步受 nice 至的影响, nice 值作为调整 CPU 时间比的权重。
多数操作系统抢占时机由进程的优先级和是否有时间片决定的,而 Linux CFS 调度器取决 于新的可运行进程消耗的处理器使用比,比当前进程小,则立刻投入运行。
Linux 调度算法
调度器类
Linux 调度器以 模块 方式提供,目的是便于不同类型的进程可以选择不同的调度器。
模块化结构叫调度器类,允许多种不同的可动态添加的调度算法并存,调度属于自己范畴的进程。
每个调度器有一个优先级,定义在 <kernel/sched.h> . 按照优先级遍历调度类,拥有一
个可执行的最高优先级的调度器胜出,选择要执行的程序。
CFS 是普通进程的调度类,称为 SCHED_NORMAL(POSIX中称为 SCHED_OTHER) 定义在 <kernel/sched_fair.c>
Unix 中的进程调度
优先级以 nice 值形式输出到用户空间。存在的问题
- 将 nice 值映射到时间片,必需将 nice 单位值对应到处理器的绝对时间,这样将导致 进程切换无法最优化进行。
- 相对 nice 值,同样和时间片的映射相关
- 执行 nice 值到时间片的映射时,需要分配一个绝对时间片,且这个时间片必须在内核 的测试范围内
- 基于优先级的调度器为了优化交互任务而唤醒相关进程的问题
公平调度
理念:进程调度的效果应如同系统具备一个理想中的完美多任务处理器。每个进程将能获得 1/n 的处理器时间 — n 为可执行进程的数量。调度器给它们无限小的时间周期,因此在 任何可测量周期内,给于 n 个进程中每个进程同样多的运行时间。
CFS 允许每一个进程运行一段时间、循环轮转、选择运行最少的进程作为下一个运行进程, 而不再分配给每个进程时间片了;在所有可运行进程总数基础上计算出一个进程应该运行多 久,而不是依靠 nice 值计算时间片。nice 值用于运行比的权重,越高的 nice 值权重越 低。
CFS 为进程设置获得的时间片底线,称为最小粒度(1ms)。
总结:
- 任何进程获得的处理器时间是由它自己和其它所有可运行进程 nice 值的相对差值决定。
- nice 值对时间片的作用是几何加权,而不是算术加权
- 确保给每个进程公平的处理器使用比,而不是一个绝对值
- CFS 并不一定总是完全公平的,当可运行进程数量过打时就不是了,因为要考虑进程时间 片最小粒度
Linux 调度器实现
时间统计
当一个进程的时间片减少到 0 时,就会被另一个减到 0 的进程抢占。
调度实体
CFS 必须确保每个进程只在公平分配给它的处理器时间内运行。定义在 <linux/sched.h>
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
};
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned int time_slice;
int nr_cpus_allowed;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
};
它作为 se 成员变量定义在 task_struct 中。
虚拟实时
vruntime 存放进程的虚拟运行时间,经过标准化的。以 ns 为单位,所以和定时器节拍
无关。作用是有助于逼近 CFS 模型的 理想多处理器。
update_curr() 实现,定义于 kernel/sched_fair.c.
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_of(cfs_rq)->clock_task;
unsigned long delta_exec;
if (unlikely(!curr))
return;
/*
* Get the amount of time the current task was running
* since the last time we changed load (this cannot
* overflow on 32 bits):
*/
delta_exec = (unsigned long)(now - curr->exec_start);
if (!delta_exec)
return;
__update_curr(cfs_rq, curr, delta_exec);
curr->exec_start = now;
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
}
计算当前进程的执行时间并放在 delta_exec 中,然后将运行时间传递给
__update_curr(), 它根据可运行数量对运行时间进行加权计算;最后将权重值与当前进
程的 vruntime 相加。
/*
* Update the current task's runtime statistics. Skip current tasks that
* are not in our scheduling class.
*/
static inline void
__update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr,
unsigned long delta_exec)
{
unsigned long delta_exec_weighted;
schedstat_set(curr->statistics.exec_max,
max((u64)delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);
delta_exec_weighted = calc_delta_fair(delta_exec, curr);
curr->vruntime += delta_exec_weighted;
update_min_vruntime(cfs_rq);
#if defined CONFIG_SMP && defined CONFIG_FAIR_GROUP_SCHED
cfs_rq->load_unacc_exec_time += delta_exec;
#endif
}
update_curr 由系统定时器周期性调用。
进程选择
选择具有最小 vruntime 的进程;CFS 使用红黑树组织可运行进程队列,可快速找到最小的 vruntime 的进程。
- 挑选任务
`__pick_next_entity()`, 定义在 `kernel/sched_fair.c` 中。
```c
static struct sched_entity *__pick_next_entity(struct sched_entity *se)
{
struct rb_node *next = rb_next(&se->run_node);
if (!next)
return NULL;
return rb_entry(next, struct sched_entity, run_node);
}
```
> \_\_pick\_next\_entity 不会遍历最左子节点,它存在 `rb_leftmost` 中。如果返回 NULL,
> 则没有可执行进程, CFS 选择 idle 任务。
- 加入进程
发生在进程变为可运行或 `fork` 创建进程时。
```c
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update the normalized vruntime before updating min_vruntime
* through callig update_curr().
*/
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
se->vruntime += cfs_rq->min_vruntime;
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
update_cfs_load(cfs_rq, 0);
account_entity_enqueue(cfs_rq, se);
update_cfs_shares(cfs_rq);
if (flags & ENQUEUE_WAKEUP) {
place_entity(cfs_rq, se, 0);
enqueue_sleeper(cfs_rq, se);
}
update_stats_enqueue(cfs_rq, se);
check_spread(cfs_rq, se);
if (se != cfs_rq->curr)
__enqueue_entity(cfs_rq, se);
se->on_rq = 1;
if (cfs_rq->nr_running == 1)
list_add_leaf_cfs_rq(cfs_rq);
}
```
更新运行时间和其它统计书据后调用 `__enqueue_entity` 进行繁重的插入操作:
```c
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
s64 key = entity_key(cfs_rq, se);
int leftmost = 1;
/*
* Find the right place in the rbtree:
*/
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
if (key < entity_key(cfs_rq, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = 0;
}
}
/*
* Maintain a cache of leftmost tree entries (it is frequently
* used):
*/
if (leftmost)
cfs_rq->rb_leftmost = &se->run_node;
rb_link_node(&se->run_node, parent, link);
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}
```
- 删除进程
发生在进程阻塞或终止时。
```c
static void
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
update_stats_dequeue(cfs_rq, se);
if (flags & DEQUEUE_SLEEP) {
#ifdef CONFIG_SCHEDSTATS
if (entity_is_task(se)) {
struct task_struct *tsk = task_of(se);
if (tsk->state & TASK_INTERRUPTIBLE)
se->statistics.sleep_start = rq_of(cfs_rq)->clock;
if (tsk->state & TASK_UNINTERRUPTIBLE)
se->statistics.block_start = rq_of(cfs_rq)->clock;
}
#endif
}
clear_buddies(cfs_rq, se);
if (se != cfs_rq->curr)
__dequeue_entity(cfs_rq, se);
se->on_rq = 0;
update_cfs_load(cfs_rq, 0);
account_entity_dequeue(cfs_rq, se);
update_min_vruntime(cfs_rq);
update_cfs_shares(cfs_rq);
/*
* Normalize the entity after updating the min_vruntime because the
* update can refer to the ->curr item and we need to reflect this
* movement in our normalized position.
*/
if (!(flags & DEQUEUE_SLEEP))
se->vruntime -= cfs_rq->min_vruntime;
}
```
实际工作交给 `__dequeue_entity` :
```c
static void __dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (cfs_rq->rb_leftmost == &se->run_node) {
struct rb_node *next_node;
next_node = rb_next(&se->run_node);
cfs_rq->rb_leftmost = next_node;
}
rb_erase(&se->run_node, &cfs_rq->tasks_timeline);
}
```
调度器入口
schedule() , 定义在 kernel/sched.h 中。作用:选择进程运行,何时将其投入运行。
先选择一个有可运行队列的最高优先级调度类,然后选择运行进程。它会调用
pick_next_task(),定义在 kernel/sched.h 中。
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
BUG(); /* the idle class will always have a runnable task */
}
CFS 中的 pick_next_task() 会调用 pick_next_entity()
睡眠和唤醒
休眠必须以轮询的方式实现。
- 等待队列
由等待某些事件组成的简单链表。内核用 `wake_queue_head_t` 代表等待队列。创建方式:
1. 静态创建 : DECLARE\_WAITQUEUE()
2. 动态创建 : init\_waitqueue\_head()
休眠推荐操作:
```c
DEFINE_WAIT(wait);
add_wait_queue(q, &wait);
while(!condition){
prepare_to_wait(&q, &wait, TASK_INTERRUPTIBLE);
if(signal_pending(current)){
/* 处理信号 */
}
schedule();
}
```
一个实例: `inotify_read()`, 负责从通知文件描述符中读取信息。定义在 `/fs/notify/inotify/inotify_user.c`
```c
static ssize_t inotify_read(struct file *file, char __user *buf,
size_t count, loff_t *pos)
{
struct fsnotify_group *group;
struct fsnotify_event *kevent;
char __user *start;
int ret;
DEFINE_WAIT(wait);
start = buf;
group = file->private_data;
while (1) {
prepare_to_wait(&group->notification_waitq, &wait, TASK_INTERRUPTIBLE);
mutex_lock(&group->notification_mutex);
kevent = get_one_event(group, count);
mutex_unlock(&group->notification_mutex);
pr_debug("%s: group=%p kevent=%p\n", __func__, group, kevent);
if (kevent) {
ret = PTR_ERR(kevent);
if (IS_ERR(kevent))
break;
ret = copy_event_to_user(group, kevent, buf);
fsnotify_put_event(kevent);
if (ret < 0)
break;
buf += ret;
count -= ret;
continue;
}
ret = -EAGAIN;
if (file->f_flags & O_NONBLOCK)
break;
ret = -EINTR;
if (signal_pending(current))
break;
if (start != buf)
break;
schedule();
}
finish_wait(&group->notification_waitq, &wait);
if (start != buf && ret != -EFAULT)
ret = buf - start;
return ret;
}
```
- 唤醒
通过 `wake_up()` 进行,唤醒指定等待队列上的所有进程。
- 调用 `try_to_wake_up()` : 设置进程状态为 `TASK_RUNNING`
- 调用 `enqueue_task()` : 将进程放入红黑树
- 如果优先级高于当前进程,需设置 `need_resched`
抢占和上下文切换
上下文切换是从一个进程切换到另一个可执行进程,由定义在 <kernel/sched.h> 中的
context_switch() 负责,由 schedule() 调用。
- 调用
switch_mm(): 切换虚拟内存 - 调用
switch_to: 切换到新进程的处理器状态,包括保存、恢复栈和寄存器以及任何 与体系结构相关的状态信息
用户抢占
- 从系统调用返回用户空间时
- 从中断处理程序返回用户空间时
内核抢占
Linux 支持完整的内核抢占,否则内核代码会一直执行,直到完成为止。2.6 版本后引入内 核抢占,内核可以在任何时间抢占正在执行的任务。
为了支持内核抢占,在 thread_info 中加入了 preempt_count 计数器,使用锁时加
1, 释放锁时减 1. 数值为 0 可抢占。
- 中断处理程序正在执行,且返回内核空间
- 内核代码再一次具有可抢占性的时候
- 内核中的任务显式的调用
schedule() - 内核的任务阻塞
实时调度策略
两种策略:
SCHED_FIFO: 同一优先级实行简单的先入先出的调度算法,高优先级直接抢占。SCHED_RR: 带有时间片的SCHED_FIFO,为实时轮流调度算法,但是是在同一优先级 的轮流。
普通进程为 SCHED_NORMAL 策略,这个由 CFS 管理,而实时策略由特殊的实时调度器管
理,定义在 <kernel/sched_rt.c 中。
使用静态优先级,保证给定优先级的实时进程总能抢占低优先级的进程。
软实时:内核调度进程,尽力使进程在限定时间到来前运行,但内核不保证总能满足这些进 程的要求。
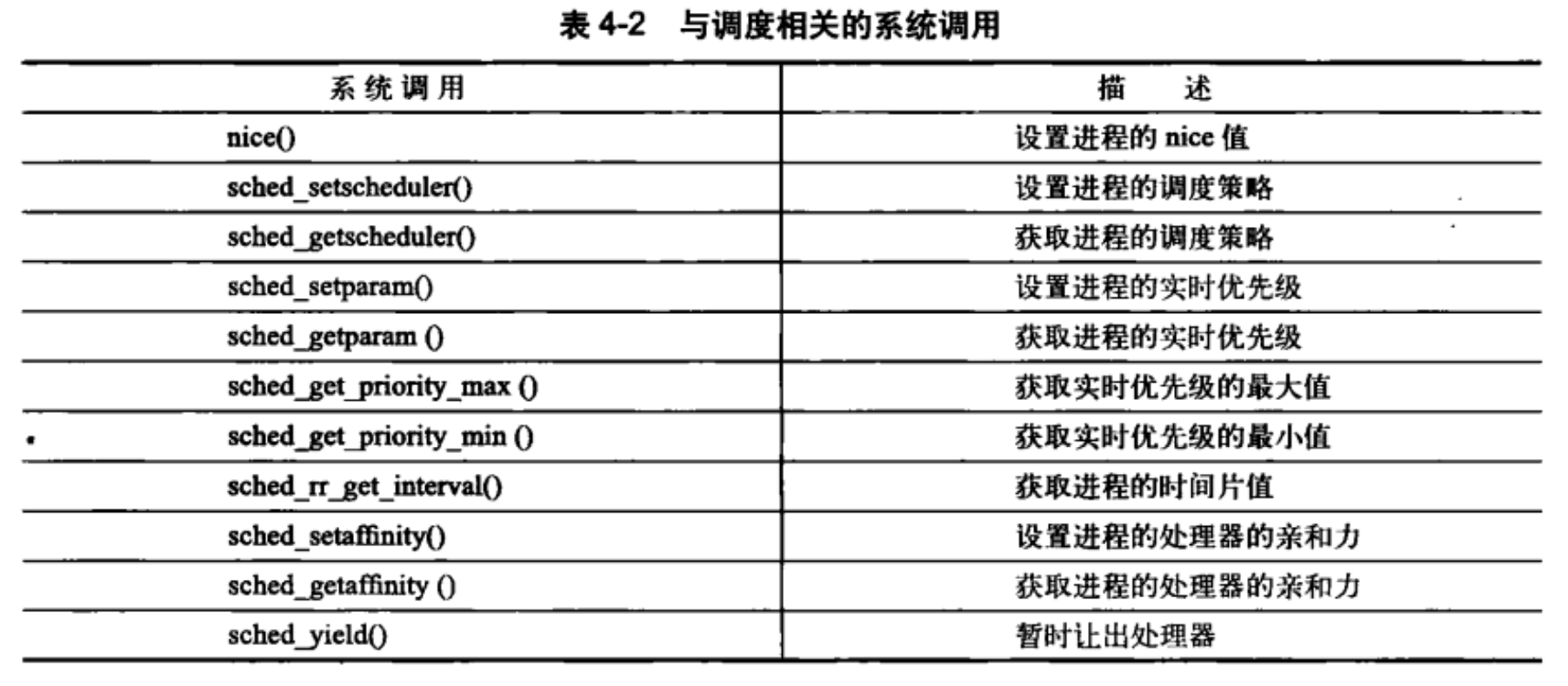
与调度相关的系统调用