/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page, though if it is a pagecache page, rmap structures can tell us
* who is mapping it.
*/structpage{unsignedlongflags;/* Atomic flags, some possibly
* updated asynchronously */atomic_t_count;/* Usage count, see below. */union{atomic_t_mapcount;/* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/struct{/* SLUB */u16inuse;u16objects;};};union{struct{unsignedlongprivate;/* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/structaddress_space*mapping;/* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/};#if USE_SPLIT_PTLOCKS
spinlock_tptl;#endif
structkmem_cache*slab;/* SLUB: Pointer to slab */structpage*first_page;/* Compound tail pages */};union{pgoff_tindex;/* Our offset within mapping. */void*freelist;/* SLUB: freelist req. slab lock */};structlist_headlru;/* Pageout list, eg. active_list
* protected by zone->lru_lock !
*//*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/#if defined(WANT_PAGE_VIRTUAL)
void*virtual;/* Kernel virtual address (NULL if
not kmapped, ie. highmem) */#endif /* WANT_PAGE_VIRTUAL */#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsignedlongdebug_flags;/* Use atomic bitops on this */#endif
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/void*shadow;#endif
};
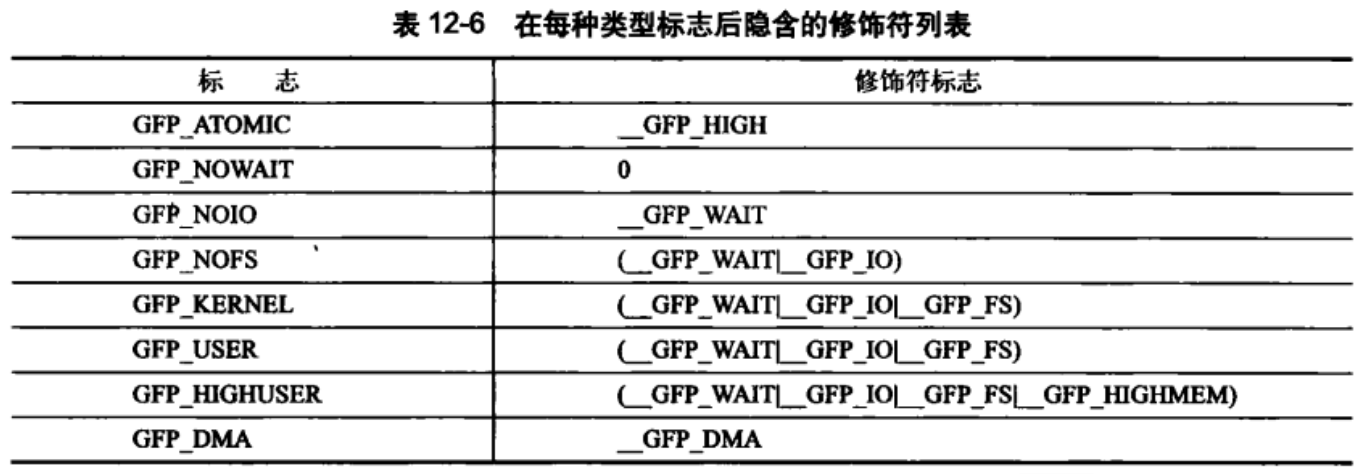
structzone{/* Fields commonly accessed by the page allocator *//* zone watermarks, access with *_wmark_pages(zone) macros */unsignedlongwatermark[NR_WMARK];/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/unsignedlongpercpu_drift_mark;/*
* We don't know if the memory that we're going to allocate will be freeable
* or/and it will be released eventually, so to avoid totally wasting several
* GB of ram we must reserve some of the lower zone memory (otherwise we risk
* to run OOM on the lower zones despite there's tons of freeable ram
* on the higher zones). This array is recalculated at runtime if the
* sysctl_lowmem_reserve_ratio sysctl changes.
*/unsignedlonglowmem_reserve[MAX_NR_ZONES];#ifdef CONFIG_NUMA
intnode;/*
* zone reclaim becomes active if more unmapped pages exist.
*/unsignedlongmin_unmapped_pages;unsignedlongmin_slab_pages;#endif
structper_cpu_pageset__percpu*pageset;/*
* free areas of different sizes
*/spinlock_tlock;intall_unreclaimable;/* All pages pinned */#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */seqlock_tspan_seqlock;#endif
structfree_areafree_area[MAX_ORDER];#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/unsignedlong*pageblock_flags;#endif /* CONFIG_SPARSEMEM */#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/unsignedintcompact_considered;unsignedintcompact_defer_shift;#endif
ZONE_PADDING(_pad1_)/* Fields commonly accessed by the page reclaim scanner */spinlock_tlru_lock;structzone_lru{structlist_headlist;}lru[NR_LRU_LISTS];structzone_reclaim_statreclaim_stat;unsignedlongpages_scanned;/* since last reclaim */unsignedlongflags;/* zone flags, see below *//* Zone statistics */atomic_long_tvm_stat[NR_VM_ZONE_STAT_ITEMS];/*
* The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
* this zone's LRU. Maintained by the pageout code.
*/unsignedintinactive_ratio;ZONE_PADDING(_pad2_)/* Rarely used or read-mostly fields *//*
* wait_table -- the array holding the hash table
* wait_table_hash_nr_entries -- the size of the hash table array
* wait_table_bits -- wait_table_size == (1 << wait_table_bits)
*
* The purpose of all these is to keep track of the people
* waiting for a page to become available and make them
* runnable again when possible. The trouble is that this
* consumes a lot of space, especially when so few things
* wait on pages at a given time. So instead of using
* per-page waitqueues, we use a waitqueue hash table.
*
* The bucket discipline is to sleep on the same queue when
* colliding and wake all in that wait queue when removing.
* When something wakes, it must check to be sure its page is
* truly available, a la thundering herd. The cost of a
* collision is great, but given the expected load of the
* table, they should be so rare as to be outweighed by the
* benefits from the saved space.
*
* __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the
* primary users of these fields, and in mm/page_alloc.c
* free_area_init_core() performs the initialization of them.
*/wait_queue_head_t*wait_table;unsignedlongwait_table_hash_nr_entries;unsignedlongwait_table_bits;/*
* Discontig memory support fields.
*/structpglist_data*zone_pgdat;/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */unsignedlongzone_start_pfn;/*
* zone_start_pfn, spanned_pages and present_pages are all
* protected by span_seqlock. It is a seqlock because it has
* to be read outside of zone->lock, and it is done in the main
* allocator path. But, it is written quite infrequently.
*
* The lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*/unsignedlongspanned_pages;/* total size, including holes */unsignedlongpresent_pages;/* amount of memory (excluding holes) *//*
* rarely used fields:
*/constchar*name;}____cacheline_internodealigned_in_smp;
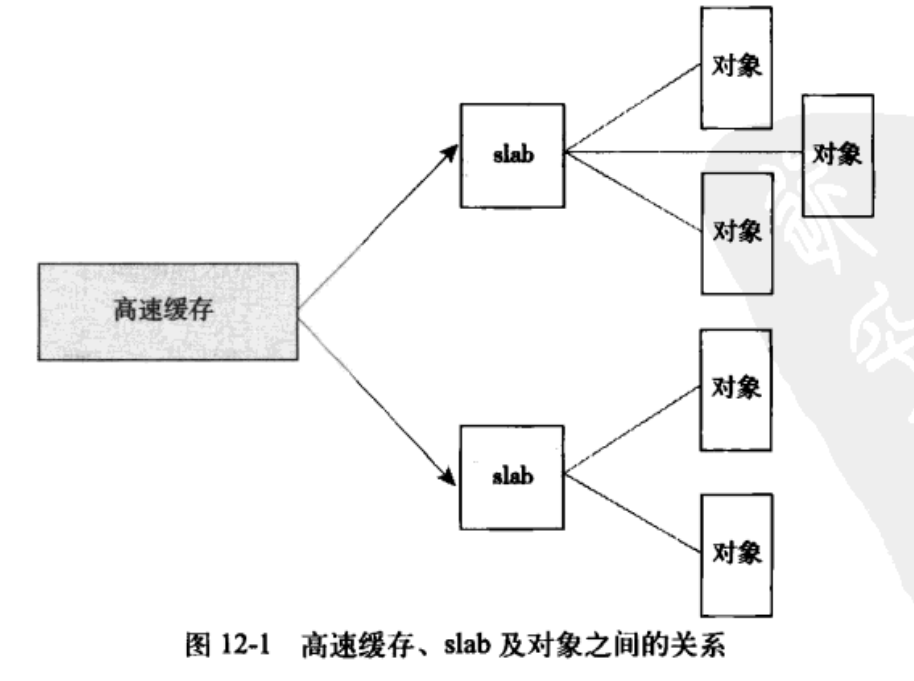
/*
* struct slab
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/structslab{union{struct{structlist_headlist;/* 满、部分或空链表 */unsignedlongcolouroff;/* slab 着色偏移量 **/void*s_mem;/* including colour offset */unsignedintinuse;/* num of objs active in slab */kmem_bufctl_tfree;unsignedshortnodeid;};structslab_rcu__slab_cover_slab_rcu;};};
staticvoid*kmem_getpages(structkmem_cache*cachep,gfp_tflags,intnodeid){structpage*page;intnr_pages;inti;#ifndef CONFIG_MMU
/*
* Nommu uses slab's for process anonymous memory allocations, and thus
* requires __GFP_COMP to properly refcount higher order allocations
*/flags|=__GFP_COMP;#endif
flags|=cachep->gfpflags;if(cachep->flags&SLAB_RECLAIM_ACCOUNT)flags|=__GFP_RECLAIMABLE;page=alloc_pages_exact_node(nodeid,flags|__GFP_NOTRACK,cachep->gfporder);if(!page)returnNULL;nr_pages=(1<<cachep->gfporder);if(cachep->flags&SLAB_RECLAIM_ACCOUNT)add_zone_page_state(page_zone(page),NR_SLAB_RECLAIMABLE,nr_pages);elseadd_zone_page_state(page_zone(page),NR_SLAB_UNRECLAIMABLE,nr_pages);for(i=0;i<nr_pages;i++)__SetPageSlab(page+i);if(kmemcheck_enabled&&!(cachep->flags&SLAB_NOTRACK)){kmemcheck_alloc_shadow(page,cachep->gfporder,flags,nodeid);if(cachep->ctor)kmemcheck_mark_uninitialized_pages(page,nr_pages);elsekmemcheck_mark_unallocated_pages(page,nr_pages);}returnpage_address(page);}